Top 10 tips for cloud adoption
If you are new to using the cloud, or are now deciding to move more workloads to the cloud – here are my top 10 tips for cloud adoption
1. Switch off dev/test when not using it
Probably the biggest advice I can give is to understand the differences between cloud and on-premises hardware. The differences include the significant change that instead of cost being capital up-front charges, all of cloud costs are variable operating expenditure. So, whilst it was common in physical (and even private virtual) infrastructure environments to have dedicated servers for production, development, test, user acceptance testing etc. – in the cloud this needs to be considered differently. When you are not doing testing or development, the cloud resource will still be incurring a cost per hour. So, if it’s not in use – power it off to save money. This should be done every night and weekend, and times when there is non development or testing occuring.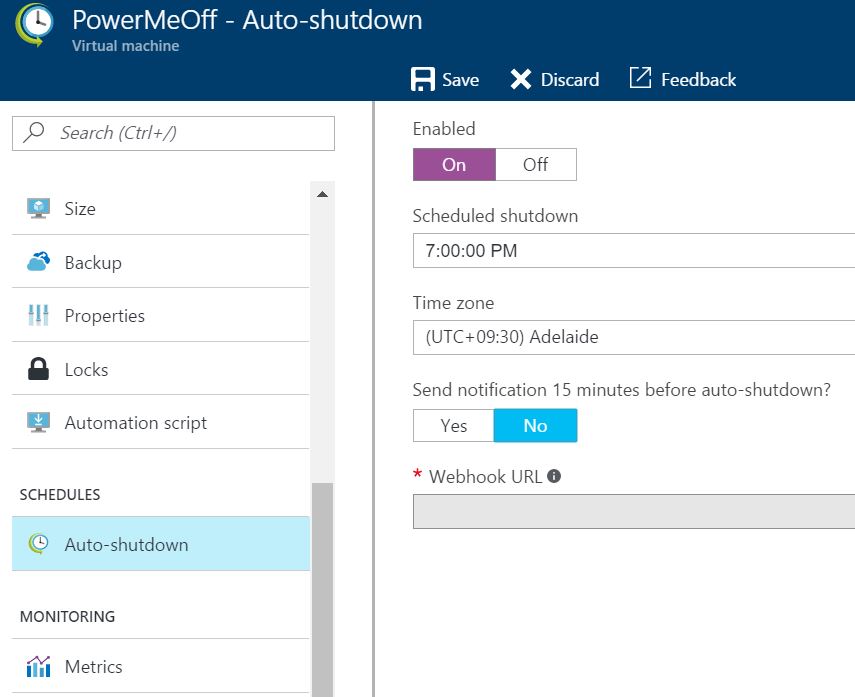
With Azure, there is an option for Auto-Shutdown of a VM – simply select it in the console. For AWS, there are multiple options, such as using a Lambda function or using CloudWatch – but it needs a little scripting development.
2. Shift your paradigm from hardware focus
 If you are coming from a virtualised environment, you may have already shifted your thinking of servers needing particular configuration, tools and agents installed. Just because you have a Windows Server, does not mean that it needs to have a backup agent, a suite of management tools, or in-OS configuration to forward out logs and monitoring data. Much of the server SOE (standard operating environment) changes that you may have done for your “gold disk” servers, or applied by Group Policy, has already been done by the IaaS provider in their image. Monitoring and log access is available without going into the virtual server, backup and other tasks are performed outside the machine, and much of the management tools you may have needed to use in the past are no longer required – do you really need to install (and license, of course) WinZip on every server? Do you really need to configure the in-OS firewall as well as the Network Security Group and the cloud provider firewall?
If you are coming from a virtualised environment, you may have already shifted your thinking of servers needing particular configuration, tools and agents installed. Just because you have a Windows Server, does not mean that it needs to have a backup agent, a suite of management tools, or in-OS configuration to forward out logs and monitoring data. Much of the server SOE (standard operating environment) changes that you may have done for your “gold disk” servers, or applied by Group Policy, has already been done by the IaaS provider in their image. Monitoring and log access is available without going into the virtual server, backup and other tasks are performed outside the machine, and much of the management tools you may have needed to use in the past are no longer required – do you really need to install (and license, of course) WinZip on every server? Do you really need to configure the in-OS firewall as well as the Network Security Group and the cloud provider firewall?
Your own need may vary, but re-analyse all the changes you normally do to your servers, keep it as plain as possible to accelerate future deployments. [wp_ad_camp_1]
3. Secure your data, connections, applications, not just your perimeter
One major variation to the above advice is around security. A vanilla server from the cloud provider will have standard controls can be probed and tested for weakness – hackers have access to the same image as you do. So, instead of securing the servers and the network perimeter (in the traditional approach taken to on-premises systems), youn need to secure your data and your applications. This may mean enabling data encryption within your application and on network connections, enabling TLS or SSL connection between servers, and ensuring you have effective authentication controls for users and for service accounts.
You can place a certain level of trust in your IaaS provider’s perimeter – they have invested a lot more in their perimeter than you ever would – but shift your focus to your data and your connections instead of the infrastructure.
4. Pay per minute is your friend, not your foe.
 Save money by understanding the model of pay per minute/hour/KB. You can tune your services and servers to reduce the costs of unnecessary waste. On the other side of the coin is the ability to consume services for a short time, incur a tiny cost, and then stop the cost all together. Spend a few days on a bit of automation for bringing up a service, configuring it and enabling connection to data, and then tearing it down until it is needed again.
Save money by understanding the model of pay per minute/hour/KB. You can tune your services and servers to reduce the costs of unnecessary waste. On the other side of the coin is the ability to consume services for a short time, incur a tiny cost, and then stop the cost all together. Spend a few days on a bit of automation for bringing up a service, configuring it and enabling connection to data, and then tearing it down until it is needed again.
5. Choose the right model, IaaS, PaaS – per application
There is no one model that will suit every need. I have a view that IaaS is dead before it reached adolescense, but it still has it’s place – particularly for legacy or highly customised applications. If the service you want to use is available as SaaS, then this often offers the best cost benefit (focus on the business need and not the need to have a particular specific application). Platform as a Service is great if you have already developed your services, have them well documented and have the source code and skilled developers.
You will need to consider the right model for each service and application. It may be that you have multiple legacy applications that can be replaced with a new SaaS app, or that you may be able to replace a single application with multiple single-purpose apps combined together.
You should consider the total end-to-end cost of each application too. Is there an additional cost for moving your license to an IaaS model, when the same product is available as a PaaS or SaaS offering? What about supporting toolsets and engineers – if you move to a SQL PaaS, do you need to have DBAs?
6. Understand your Geo-location and redundancy capabilities
With the paradigm of a physical on-premises infrastructure, there was a focus on redundancy – a N+1 power supply, redundant disks in a RAID set, multi-pathed fibre and Ethernet, BGP routers and paired CRAC and UPS units. All of this redundancy is focussed on hardware failing – something that you no longer have control over in the Cloud. Your datacentre would have needed a backup location, with the capability to fail-over to ensure uptime for your applications.
 Now, with cloud, you focus should be on ensuring applications are available by using the controls and services available to you through your cloud provider. This can simplify your design considerably, as much of the responsibility for uptime and availability is out of your control.
Now, with cloud, you focus should be on ensuring applications are available by using the controls and services available to you through your cloud provider. This can simplify your design considerably, as much of the responsibility for uptime and availability is out of your control.
Where the service provider is only issuing a 99.9% SLA on each component (not the whole service), you cannot provide any higher availability unless you design your application to span geographic regions – to cope with the limitations of your provider. This needs to be analysed and understood so that you don’t over-invest in something that provides no benefit, and conversely that you don’t run the risk of being down for an extended amount of time when it is out of your control (but still within their SLA).[wp_ad_camp_1]
7. Make it easy for self-service, to avoid Shadow IT spreading
Using a cloud service is easy. Anyone with a credit card can purchase a service (or sign up for a free service). This is fine, until they come to you and ask for it to be integrated – to use the Active Directory for authentication, or to draw on the Exchange address list. The scourge of Shadow IT is ever present, and only growing. However, if you provide access to your chosen cloud provider, but limit the selection of their services, you can at least control some of the spread. The cost of a few extra services within your portal is considerably less than the effort to migrate or integrate a repository that has been secretly in use by another department for months or years.
8. Expect a change in services and capabilities
 The Cloud is constantly getting new features and admin menu functions. You need to consider that things will change – new limits (or increased capacities), decreasing costs, and in particular, changes in available services. The look and feel – particularly of admin functions – will change too.
The Cloud is constantly getting new features and admin menu functions. You need to consider that things will change – new limits (or increased capacities), decreasing costs, and in particular, changes in available services. The look and feel – particularly of admin functions – will change too.
Don’t customise your application or service too much – because the cloud provider may change the system, be aware that features and capabilities (including commands used in scripts) can get deprecated, and even have parameters changed or removed.
If you take the same view of cloud that you have taken for your internal infrastructure and IT approach, you may expect to use multiple third-party tools and features. For example, it is tempting to keep using the same monitoring solution, backup software or anti-malware product set. However, using additional services (particularly when these features are either not required or already natively provided in the cloud) can add complexity that can break when either the 3rd party changes, or the cloud provider changes. When your favourite monitoring company ends up stopping one service to move onto a different approach – how will this affect your environment?
When adopting the cloud, keep it as vanilla as possible, try not to use too many custom workarounds – instead, alter your approach to take advantage of the way that the Cloud provider offers their services.
9. Plan to cope with failure – pets vs. cattle.
 When you had your environment on-premises, you were able to design failure out of the system; redundant everything, low latency and high performance interconnects, carefully managed systems. When you move to the cloud, someone else looks after it. Yes, the major cloud providers (and most of the smaller ones) will take an even more professional approach of ensuring maximum uptime and internal performance – however, your individual services that you consume may be very widely distributed and subject to a whole new set of risks.
When you had your environment on-premises, you were able to design failure out of the system; redundant everything, low latency and high performance interconnects, carefully managed systems. When you move to the cloud, someone else looks after it. Yes, the major cloud providers (and most of the smaller ones) will take an even more professional approach of ensuring maximum uptime and internal performance – however, your individual services that you consume may be very widely distributed and subject to a whole new set of risks.
The types of failure to plan for include;
- OS crash/bluescreen
- High latency between on-premises and in-cloud (or intra-cloud or inter-AZ)
- Firewall/NSG misconfiguration or change
- Code change error – particularly between components like PaaS and SaaS
- Administrative error
- Cloud provider change (including point 8 above)
The main point is, there will be problems that occur at some time. Your application or service must be designed to be able to cope with the problems;
- Utilise load-balancing services to distribute connections in the event of one failing
- Consider creating replicas of services and servers, and scripts that can bring a new/running service up quickly
- Build in helpful error screens and messages – instead of a “500” error, state something helpful that will allow your customers and users to either be able to report the error, or know that it is being addressed.
- Design your applications for fast spin-up, autoscaling and cloning. If you deploy a new application service, will it be able to coalesce with other servers in the group and take over user connections, or does an administrator need to spend time on configuring both the new machine and the existing (perhaps unavailable…) machine?
So, instead of treating your servers as pets (where each one is cared for, nurtured, named and carefully watched), treat your services as cattle (transient, numbered instead of named, available in numbers, something goes wrong with one then just dispose of it and carry on).
10. Consider re-designing your app, or re-investigating your business process for Cloud capability
The final point is probably the most complex to implement. Taking in mind all the above advice, it will pay well to make a consideration towards new approaches that are more specific to the paradigm that is cloud. If you have an application that requires to run with administrator privileges, needs low latency between components on undefined ports, is heavily customised and integration is hard-coded manually – then it’s not the best application to move to the Cloud. However, it might be more effective to investigate your business process and operational requirements – and make a change to your business so that you can use a new tool that is born in the cloud.
If you have a self-developed application, where you have access to the source code, then what can you do to re-design your application so that it is ready for Cloud? You need to consider that the platform version may change underneath you, that there may be connectivity delays between components and clients, and you need to allow servers/services to be shut down and duplicated without any damage or corruption caused.