Lessons from the CrowdStrike incident
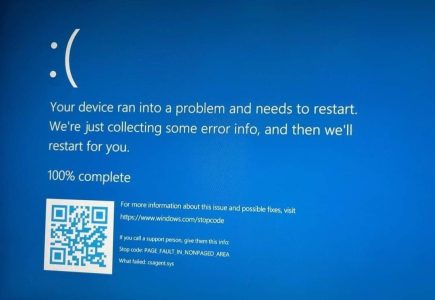
Yesterday, there was a world-wide incident that affected computers running CrowdStrike Falcon, where there was a conflict between the vendor’s anti-malware protection and the Windows sensor, resulting in a BSOD and unresponsive computers. This is a major incident that was effectively the effective impact as we were expecting from the Y2K bug, but this time it actually affected the world. So, what are the lessons from the CrowdStrike incident that we can gain?
Learn from your mistakes
A saying I like to use often is “it is good to learn from your mistakes, but it is better to learn from others’ mistakes“. In this situation, I think it is important that we all learn the lessons from the CrowdStrike incident. We can learn from what went wrong, the impact and also the response.
Learning from what went wrong
As the update to their sensor was pushed across the whole world at once, computers started failing immediately. This is not the same as a Microsoft Patch Tuesday update, where the updates are made available for administrators to test and install, instead the cybersecurity company just pushes out the update to all computers with no confirmation from customers. There was no opportuity for clients to test, and also no schedule for clients to delay the patch.
I have had other war stories about how an anti-virus product actually causes problems – like deleting useful files, or preventing access to systems. This is because security products have a very deep and complete access to an operating system, which helps them protect computers, but if they go wrong (like using all CPU cycles), then it has a deep impact.
Technical lessons
Within less than 75 minutes, CrowdStrike had reverted the content, and had a fix in less than six hours. However, the affected machines were in a state that meant the fix could not be applied – a bluescreened machine is not administerable or usable. Whilst there were reports that constantly rebooting the computer would improve the chances that the Falcon client could download and apply an update before it crashed (rebooting around 15-20 times seems to work), otherwise the manual fix was to manually delete a few files from the CrowdStrike folder. Unfortunately, this requires local access to a machine, and requires the local adminstrator password to log in. Plus, if the hard disk is encrypted, this requires that the unique BitLocker code is entered, manually, into each computer to gain access to the hard drive. Whilst a computer is in the bluescreen state, it cannot be remotely or automatically fixed.
Deeper technical analysis revealed that the Falcon client was trying to read memory address 0x9c, which is invalid for use by any program, and so Windows’ internal mechanisms will terminate the process, which halts the computer. The lessons that Microsoft will learn from this, is how to have a graceful ejection of defective drivers, instead of a panic.
Lessons from the impact
Surprisingly, the world seems to be more accepting of major IT outages. Despite the initial reaction that was believing that it was a cybersecurity incident, or a hack, the world was frustrated at the impact, but sort of accepted that it was an IT outage. There was turmoil caused by the fact that systems and services were not available, but society has now come to accept that there are sometimes IT incidents that … just happen.
Of course, there are the business leaders who shout at IT to demand “when will it be fixed?”, without consideration that un-planned problems that are caused by external companies can have no projected fix time, until the 3rd party announces the fix (or workaround).

However, there is more of an understanding now for the need for Business Continuity Planning, and finding alternative processes and systems for when IT resources are no longer available – including paper processes. It is important to remember that for all cybersecurity planning, recovery and alternative methods of working (a BCP) is required.
We also discovered just how many people are using the much loved CrowdStrike software (over 29,000 companies) – and how widespread an outage can be, when a cybersecurity company has a problem. With so many people using the same software, IT leaders are starting to recognise that this is actually a vulnerability – not just with the product being at risk of taking down your systems, but also what happens if the cybersecurity / anti-malware software is not able to detect and protect from another type of attack?
Lessons from the response
Workaround were found, advice was distributed, and the IT world rallied to try and get everything working again. IT professionals around the world had their response plans tested – and many companies were found to be lacking. Panic, inappropriate or invalid responses, jumping to an assumption that it was a cyber attack, and even taking drastic action like disconnecting or powering off en-masse.
It became obvious that many businesses have not considered how they can continue to operate without their IT systems – manual workarounds or paper processes, instead of just shutting up shop. We can also see how deeply dependent modern society is on technology, and in particular, Windows.
Conclusion
I actually think that this incident was a really good thing. It was a wake-up call to many organisations (including those whom were not directly impacted), that they need to have an ability to continue to service customers when they suffer an IT outage. We will see knee-jerk reactions from IT companies, governments and regulators, demanding more limitations and controls on software updates. Perhaps we will also see changes by anti-virus companies to distribute their updates in smaller tranches, instead of everywhere at once. We will also probably see three things from CrowdStrike; it will either fail, grow stronger, or change name.